2021 年 01 月 18 日,我作为签定了三方的同学入职了阿里云(杭州)实习。2021 年 07 月 05 日,结束实习,正式入职。2022 年 07 月 06 日,正式离职,结束了这段阿里之旅,共计 367 天(535 天)。
离职前的这一周,收到了 Leader 送的周年纪念品和公司给的“一年香”徽章及工牌带,谢谢 Leader,谢谢公司。


还记得我参加校招面试的时候,有面试官问过我:“你工作之后最想获得什么?”我答:“加深技术深度,拓宽技术广度。”但面试官语重心长地说:“你工作之后会发现,技术并不是最重要的。”现在的我切实感受到了,技术重要,但确实不是最重要的。技术要为业务服务,通过业务拿到了好结果,才能更好地体现技术的价值。
还记得参加工作之前,我认为赚钱是最重要的,但工作之后恰逢疫情反复,切身感受到一家人平安、幸福、快乐才是最重要的。在过去一年多的时间里,我和老婆分居两地,平均两周见一次,聚少离多。每次见面最头疼的不仅是往返近 18 小时的距离,还有疫情政策的变幻无常。因为杭州和广州在两个省,属于跨省通行,所以在政策上更为严格。每次见面不仅要安排出行时间、买票,还要分别查询两个城市的疫情政策,且不乏定好了行程之后出现突发状况导致无法出行。所以,我辞职来广州了。
在过去一年多的时间里,因为异地,我们两个人成了飞机、高铁的“常客”。一开始她趁着公司有苏州的出差机会,申请到苏州出差了两个多月,这样我们每周坐一个多小时的高铁就能见面了。项目结束后,我们就大多乘飞机见面。下图是我的乘机航线图,她的乘机次数比我的还多。在异地的这段时间里,她来找我的次数比我找她的次数多很多,以至于有朋友说“一直都是看你老婆来找你”,哈哈哈。
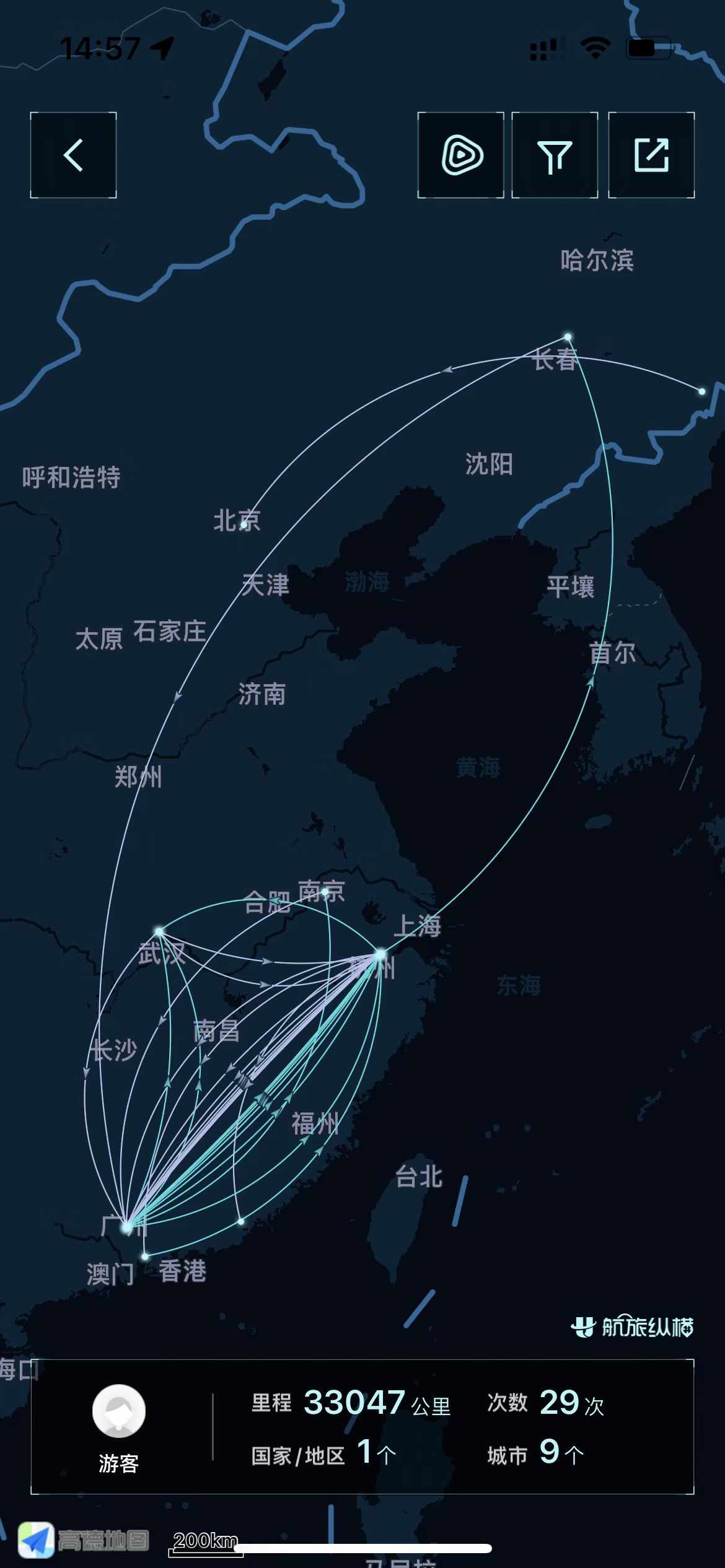
记得有一次,她从杭州回广州,坐地铁到了萧山机场却发现必须要核酸报告,因为前一天更新了政策,但航空公司没通知我们,我们也没注意到。如果是我遇到这样的事,我肯定非常生气,甚至迁怒于对方。但她在告诉我这件事的时候,语气没有丝毫不好,而是说:“我们又可以待一天啦,晚上我们一起去吃猪肚鸡好不。”我知道她也烦、也累,她坐了两个小时地铁才到机场又得坐回来,明天还得再坐两个小时地铁过去。曾经有同事问我,是什么让你决定结婚,我没有回答,现在我想说,可能就是这样的点点滴滴吧。
当然,在职一年多,从熟悉团队、熟悉项目,到成为了项目 owner。离职则意味着失去了熟悉的团队,熟悉的项目,要重新找工作并融入。但是,哪有两全齐美的事,不都是有得有失嘛。新的风险和挑战,也就意味着新的机遇,我相信自己!
谈完了现状,那么也分享一下我接下来的安排。在过去一年多的时间里,我自认为无论是在技术上,还是在工作的方式方法上,都有了极大的成长,但也存在着知其然不知其所以然的部分。所以我想用一个月到一个半月的时间,整理这一年多以来的所学所想,并搞定之前不知其所以然的部分。再重新过一遍 HTML、CSS、JavaScript 巩固基础。学习学习算法、Node、Webpack、Vite 和计算机基础等相关知识。
此外,我维护的《现代 JavaScript 教程》也有一定的待更新量,这段时间我再把教程系统地更新一下。之后我计划以每月一版的更新节奏,形成月报发布出来。
学习是一方面,代码也不能放下。在学习的过程中也要多实际操练操练,多总结,多分享。
预计在八月中下旬,开始投递简历,寻找下一份工作。我期望能够找到在业务上有前景,我认可,也认可我的一份工作和一群人。
凡是过往,皆为序章。
学文来啦!
]]>